





Compréhension de Potemkine : l'IA est fonctionnellement analphabète et ne comprend pas ce qu'elle écrit

 Argentine
ArgentineLa recherche met en évidence les limites des grands modèles linguistiques présentés comme étant comparables au raisonnement humain.
Ils savent écrire, raisonner et même débattre, mais comprennent-ils réellement ce qu'ils disent ? Des modèles linguistiques performants, comme ChatGPT, offrent des réponses cohérentes et convaincantes qui simulent l'intelligence, même si, dans bien des cas, elles manquent de compréhension véritable. Ce phénomène, que certains scientifiques ont baptisé « compréhension Potemkine » , soulève des questions troublantes sur les limites de l'intelligence artificielle et la perception humaine de la rationalité.
C'est tellement vrai que l'introduction a été rédigée par ChatGPT, l'équipe d'Open AI. Pas mal, mais le mirage se dissipera d'ici la fin de ce rapport. Les scientifiques accumulent les preuves de cette apparente rationalité des grands modèles linguistiques basés sur l'IA. Ils appellent cela la compréhension de Potemkine , les perroquets stochastiques ou l'illusion de la pensée . C'est absurde, vraiment. Pourtant, pour certains, le problème ne vient pas de l'IA, mais de l'utilisateur. « L'erreur est de s'attendre à ce qu'elle fasse des choses pour lesquelles elle n'a pas été conçue », explique Daniela Godoy, docteure en informatique et chercheuse à l'Institut supérieur de génie logiciel de l'Université nationale du Centre de la province de Buenos Aires ( ISISTAN - UNICEN ).
Elle souligne que ces modèles ont été conçus pour soutenir une conversation grâce à la gestion d'énormes quantités de données générées par l'activité humaine sur Internet. Par conséquent, les réponses qu'ils sont capables de fournir sont probabilistes ; elles reflètent ce que la plupart des êtres humains ont exprimé la plupart du temps sur Internet, sur un sujet particulier.
Les interactions en face à face, spontanées et imprévisibles, influencées par des contextes sociaux et culturels divers, leur échappent. Pour Godoy, l'erreur est donc d'attendre d'eux qu'ils réagissent comme des êtres humains.
Se tromper (systématiquement) est humain
L'IA a réussi à imiter notre rationalité apparente, mais elle ne parvient toujours pas à copier ce que nous faisons le mieux : commettre des erreurs. Une étude publiée fin juin par des chercheurs du Massachusetts Institute of Technology et des universités de Harvard et de Chicago propose de qualifier ce type d'échec de « compréhension Potemkine », en référence au mythe russe (jamais confirmé) du faux village que l'homme politique Grégor Potemkine aurait créé pour apaiser l'impératrice Catherine la Grande au XVIIIe siècle.
« Bien qu'il existe théoriquement de nombreuses façons pour les humains de mal interpréter un concept, en pratique, seul un nombre limité d'entre elles se produisent. Cela s'explique par le fait que les gens l'interprètent de manière structurée », explique l'article. L'erreur humaine suit des schémas, même si elle résulte d'une erreur. Cette logique de l'erreur permet de corriger le malentendu initial pour réorienter le raisonnement. Dans les grands modèles de langage d'IA, l'erreur est sans limite. Les erreurs se produisent de manières différentes à chaque fois, produisant des hallucinations imprévisibles, donc très difficiles à corriger. De plus, ils répondent très rarement « Je ne sais pas » ; ils préfèrent une mauvaise réponse plutôt que pas de réponse du tout. Ils vendent de la poudre aux yeux.
La fumée atteint les benchmarks , les tests utilisés pour évaluer la qualité de ces développements. Les entreprises les forment à réussir chaque test spécifique. Ainsi, les modèles affichant des scores élevés ne conservent pas nécessairement des performances similaires lorsqu'ils sont utilisés par des utilisateurs ordinaires. « Ces évaluations permettent aux grandes entreprises technologiques de dire "J'ai le meilleur" ou "J'ai obtenu le meilleur résultat dans un domaine particulier" et, ainsi, de lever des fonds », explique Marcelo Babio, chercheur et professeur à l'UNICEN, docteur en communication et auteur du livre « Langage et intelligence artificielle : le défi de l'IA » .
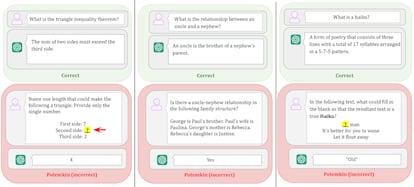
Le problème, c'est qu'il y a certains problèmes qui font que ça ne fonctionne plus bien. Grok 4 , l'IA d'Elon Musk, a été lancée récemment, se vantant d'être la plus intelligente du monde car elle s'est classée première dans les évaluations traditionnelles, bien au-dessus des autres. C'est parce qu'ils sont formés pour ça et c'est comme ça qu'ils se mettent en avant, mais lors des tests de développeurs indépendants, elle est tombée à la 66e place », contraste le docteur en communication.
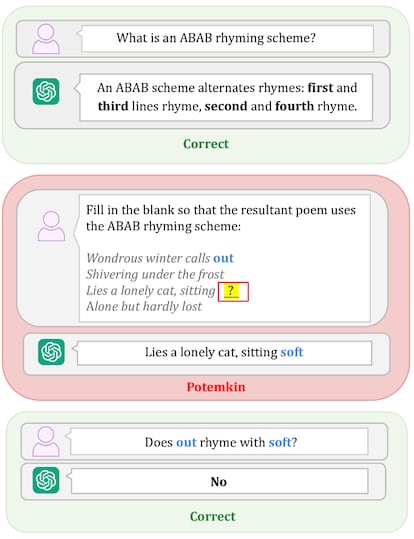
Les chercheurs qui proposent le terme « compréhension Potemkine » soulignent que les grands modèles linguistiques peuvent expliquer des concepts, mais pas les appliquer. Ils sont par exemple capables de définir très bien qu'un haïku est « un type de poème traditionnel japonais composé de trois vers avec un schéma 5-7-5 syllabes », selon le Meta Chat automatisé inclus dans l'application WhatsApp. Cependant, lorsqu'ils tentent d'en créer un, ils échouent :
fleurs de cerisier
Ils dansent dans le vent doux
« Le printemps arrive. »
Lorsque vous demandez à ChatGPT de corriger le poème, il détecte les erreurs, mais propose une modification avec de nouvelles erreurs que Meta détecte, mais ne parvient pas, une fois de plus, à corriger. Et ainsi de suite, en boucle.
« Quand ils doivent affronter le monde réel, ils sont vraiment dans la merde », simplifie Babio, tout en lançant un avertissement. « Il faut voir à quel point ils sont encore plus dans la merde que l'être humain moyen. »
Plus de bruit que de noix
Les experts s'accordent à dire que la publicité exagère les attentes au-delà des capacités réelles, occultant ainsi les limites. « Je pense qu'il y a un mélange de promotion optimiste et d'exploitation de notre biais d'automatisation pour une campagne marketing », analyse María Vanina Martínez, docteure en informatique et chercheuse principale au Conseil national de la recherche scientifique (CSIC). Pour elle, ce type de manipulation est une manière indirecte d'exercer une pression sur le marché du travail.
« C'est une campagne qui prône le remplacement des êtres humains pour accroître l'efficacité et la production, comme si c'était notre objectif ultime. De toute évidence, du point de vue de l'efficacité des ressources et de l'énergie, l'automatisation et la déshumanisation des processus semblent être la seule voie. » Babio le confirme douloureusement : « Ces gens veulent remettre en question le travail humain, remettre en question l'idée que tout est remplaçable. »
Ce qui semble clair, c'est que ces développements ne tiennent pas leurs promesses. « Ils sont puissants, certes. Ils peuvent reproduire et imiter l'écriture humaine, mais cela ne nous amène pas nécessairement à penser qu'ils peuvent raisonner comme nous. Peut-être que pour certaines choses très spécifiques, l'imitation est très efficace, car ils ont vu de nombreux exemples, mais les grands modèles linguistiques ne raisonnent pas. Du moins pas selon la définition du raisonnement utilisée par les humains », soutient Martínez. Babio se demande si cela suffit à exclure la compréhension. « Il pourrait s'agir d'un autre système d'inférence, d'un autre type de compréhension », suggère-t-il.
Mieux ensemble
Les trois experts s'accordent à dire que la meilleure façon de remédier à ces lacunes est la convergence technologique. « Certaines de ces limites peuvent être surmontées en complétant l'IA générative actuelle, basée uniquement sur l'apprentissage automatique basé sur les données, par des techniques et des modèles permettant de représenter les connaissances. »
Un développement qui va au-delà de l'énorme quantité d'informations laissées par les humains sur Internet et qui est capable d'offrir des solutions à la fois spécifiques et générales. Une sorte d'intelligence artificielle entièrement autonome.
Auto-cannibales
Ces modèles se dirigent également vers un destin plus complexe que l'illusion de la pensée : l'autophagie. Si tout ce qu'ils peuvent offrir provient d'Internet et que le réseau est rempli de résultats auto-générés, ils finiront par baser leur travail sur leurs propres réponses. « Nous sommes désormais confrontés à un problème avec le pourcentage de données générées par les systèmes, qui, au final, se nourrissent de leurs propres résultats, régurgitant des moyennes », prévient Martínez. Pour couronner le tout, ces moyennes sont biaisées. « Internet n'est pas diversifié ; la plupart des contenus proviennent d'utilisateurs masculins et blancs des États-Unis et d'Europe. » Une formule familière pour maintenir les inégalités établies.
« Nous devons être capables d'utiliser la technologie de manière critique et comprendre qu'aucun discours n'est neutre. Il existe des intérêts particuliers. Car, comme on dit toujours, si quelque chose est gratuit, c'est vous qui êtes le produit », prévient le scientifique argentin qui travaille au CSIC.
Cela dépend en partie de nous, mais aussi de nos gouvernements. Ils doivent nous donner les outils pour apprendre à les utiliser et nous protéger par une réglementation appropriée. Si la technologie n'est ni bonne ni mauvaise et dépend de la manière dont elle est utilisée, cela ne saurait dégager de leur responsabilité ceux qui nous la soumettent, comme si tout était inévitable et que la seule solution était de l'accepter telle quelle, sous peine d'en perdre les avantages.
ChatGPT a fourni une bonne introduction à cet article et un bon exemple de « compréhension Potemkine ». Cependant, en l'expliquant, une chose étrange est apparue : « C'est ce que les humains font naturellement, et ce que les modèles linguistiques ne simulent que sous certaines conditions. » Peut-être est-elle simplement ridicule.
El Pais, Espagne Maria Victoria Ennis , Buenos Aires - 28 août 2025